Installing big data technologies in a nutshell : Hadoop HDFS & Mapreduce, Yarn, Hive, Hbase, Sqoop and Spark
Hadoop in pseudodistributed mode
Pseudodistributed mode is the mode that enables you to create a Hadoop cluster of 1 node on your PC. Pseudodistributed mode is the step before going to the real distributed cluster.
To install Hadoop 1.2.1 :
wget http://mirrors.ircam.fr/pub/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
tar xvzf hadoop-1.2.1.tar.gz
export HADOOP_INSTALL=~/hadoop-1.2.1
export PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin
To check Hadoop is correctly installed, type hadoop version.
Hadoop will be by default the standalone mode. It will use the local file system (file:///) and a local job tracker.
Let’s go further with pseudodistributed mode.
To enable password-less start :
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
To check, type ssh localhost.
(On Mac OS activate Settings > Sharing > Remote Login)
HDFS
To use HDFS as default, in conf/core-site.xml :
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost</value>
</property>
</configuration>in conf/hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>To format the HDFS namenode :
hadoop namenode -format
To start HDFS :
start-dfs.sh
The namenode will be accessible at http://localhost:50070/.
Mapreduce 1
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:8021</value>
</property>
</configuration>To start the MapReduce 1
start-mapred.sh
The jobtracker will be available at http://localhost:50030/.
Mapreduce 2 (Yarn)
In conf/yarn-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8032</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
</configuration>To start
start-yarn.sh
The resource manager will be available at http://localhost:8088/.
Now you’re ready to submit your first map reduce job !
Hive
Hive is the SQL-like engine based on Hadoop HDFS + MapReduce.
To install Hive, you should have installed Hadoop before, and
wget http://apache.crihan.fr/dist/hive/hive-1.1.0/apache-hive-1.1.0-bin.tar.gz
tar xzf apache-hive-1.1.0-bin.tar.gz
export HIVE_INSTALL=~/apache-hive-1.1.0-bin
export PATH=$PATH:$HIVE_INSTALL/bin
To launch the Hive shell, type hive.
Just check everything works by creating your first table :
hive -e "create table dummy (value STRING) ;"
hive -e "show tables;"
Now you’re ready to query high volumes of data as if you were in MYSQL !
Hbase
Hbase is a great NO-SQL database, based on Hadoop HDFS. To simplify, it is a database with only one key, that is ordered, and split into regions distributed over the cluster of nodes in a redundant way. It’s particularly useful when you have millions of writes to perform simultanuously on billions of documents - where no traditional database can do the job - such as in the case of a social application with many users that like and comment many user-generated contents.
To install Hbase :
wget http://mirrors.ircam.fr/pub/apache/hbase/hbase-1.0.0/hbase-1.0.0-bin.tar.gz
tar xzf hbase-1.0.0-bin.tar.gz
export HBASE_HOME=~/hbase-1.0.0
export PATH=$PATH:$HBASE_HOME/bin
export JAVA_HOME=/usr
(on Mac you cannot set JAVA_HOME to /usr/bin/java… if you set it to /usr, it will use )
In conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///Users/christopherbourez/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/Users/christopherbourez/zookeeper</value>
</property>
</configuration>To start the database :
start-hbase.sh
To launch the Hbase shell, type hbase shell and you can run your commands
version
status
create 'table1', 'columnfamily'
put 'table1', 'row1', 'columnfamily:a', 'value1'
list
scan 'table1'
get 'table1', 'row1'
disable 'table1'; drop 'table1'
Sqoop
Sqoop is a great connector to perform import / export between a database and HDFS.
wget http://apache.crihan.fr/dist/sqoop/1.4.5/sqoop-1.4.5.bin__hadoop-1.0.0.tar.gz
tar xzf sqoop-1.4.5.bin__hadoop-1.0.0.tar.gz
export HADOOP_COMMON_HOME=~/hadoop-1.2.1
export HADOOP_MAPRED_HOME=~/hadoop-1.2.1
export HCAT_HOME=~/hive/hcatalog
export SCOOP_HOME=~/sqoop-1.4.5.bin__hadoop-0.23
export PATH=$PATH:$SCOOP_HOME/bin
To check it works, type sqoop help.
Spark
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.3.0-bin-hadoop1.tgz
tar xvzf spark-1.3.0-bin-hadoop1.tgz
To start Spark master and slaves :
~/spark-1.3.0-bin-hadoop1/sbin/start-all.sh
Spark interface will be available at http://localhost:8080/
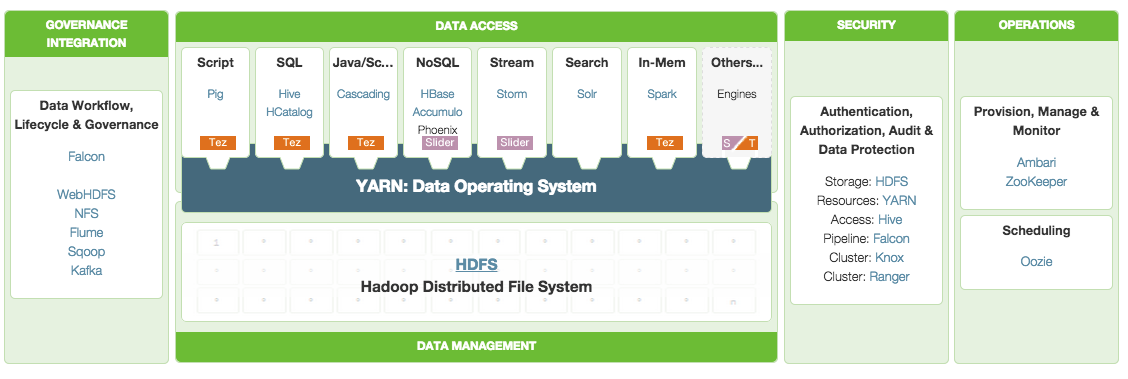
To conclude, here is a nice classification of the different levels of interactions, from @Hortonworks :
Don’t forget to stop the processes. List running processes with jps command and stop them with :
stop-dfs.sh
stop-mapred.sh
stop-hbase.sh
~/spark-1.3.0-bin-hadoop1/sbin/stop-all.sh