Image annotations : which file format and what features for an annotation tool?
UPDATE! : my Fast Image Annotation Tool for Computer Vision following these guidelines has just been released ! Have a look !
File Format
This is a good question when you start a computer vision project. You are going to annotate your pictures in a format that will serve different computer vision tools for training.
In the article about creating an object dectector with OpenCV traincascade algorithm, we saw the OpenCV format that has main drawbacks :
-
no orientated rectangles : some real world situations require to take orientation into consideration
-
no class : OpenCV format is designed to train only one category of detector
-
separation of “positives” and “negatives”, that are not annotations, but more a format for a specific category training.
The first solution is to create CSV files, one annotation per line, in the OpenCV Rect format, where the line contains the top left corner coordinates of the annotation rectangle (x,y), its width, height and the class of the annotated object (if I annotate a letter for example, it will be the letter itself) :
path,class,x,y,w,h

To my point of view, the best format is not the Rect format, but the RotatedRect format with the center point coordinates and orientation of the annotation rectangle :
path,class,center_x,center_y,w,h,o
because it will be a more general case, while orientations are very common, and will enable you to use the same tools to work on your data, extract rectangles, etc in the case of orientation. In this format, it will be also quite easy to work without the orientation by ignoring the last column, if wanted.

It is also possible to go further by adding perspective information and rotation on other axis, and in any case, center position is better than top left corner position for such description.
An alternative would be the polygon format (vector of points) which has less meaning than the transformation format (rotation parameters, affine parameters, …) for computer vision tasks such as prediction (for me, all methods based on “contours” or “signal processing” are outdated - except mean subtraction and normalization).
I will also give 3 other precious advices :
-
coordinates have to be written for the original-sized image (not a resized image), because sometimes, you will have to extract parts of the image and read some data in them, and full size images will give a better recognition quality than resized images.
-
if there are two or more objects to annotate in the image, one line per annotation in the CSV file rather than a list
-
save the CSV file either in the image directory, or next to your image directory so that image path can be relative paths, because absolute paths will not work on different computers. The latter solution, next to the image directory, is better because you can include in the same CSV file two different image folders, for very common multi-class training, such as “birds images” and “animals images” in the following example :
iMacdeCstopher2:MyData christopher$ tree . ├── my_animals_images.csv ├── my_birds_images.csv ├── my_birds_images │ ├── p1.jpg │ ├── p10.jpg │ ├── p11.jpg │ ├── p12.jpg │ ├── p13.jpg │ ├── p14.jpg │ └── p15.jpg ├── my_cats_images.csv ├── my_cats_images │ ├── p1.jpg
Annotation tool
A good annotation tool should enable you to feed it with precomputed bounding boxes to help annotation. Precomputed rectangles are potential places where objects might be in the image. This will save you the fastidious task of drawing and positioning the annotation rectangles. An algorithm will instead present you a selection of potential annotations, for which you just have to type the class of the object, and go from a potential position to another one just with the keyboard :

The algorithm to precompute bounding boxes will depend a lot on the task, and is separated from the main annotation tool. For example, for letter bounding boxes, the findContours OpenCV method is very convenient. You can also re-use previously trained classifiers.
Once the class of the rectangle has been saved, the rectangle becomes yellow, the current active one is blue, and the next ones green :

You should be able to erase a wrongly proposed box :
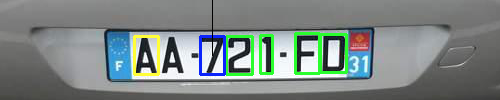
Or rescale, rotate, or reposition the proposed rectangle, or add a new one manually :

Lastly, you should be able to resume your work (reload previously saved data) :
In case rectangles are too close or two small compared to the definition of the image, you should be able to have an alternative, not drawing all rectangles, such as a cross (+) mode presented below :

Well done!