TinkerPop for graph databases : the end of Active Record and relational databases
Anti-patterns with relational databases and Active Records
It’s been a long time since I prefer to avoid some aspects of relational databases and SQL queries.
MySQL is great for simple CRUD operations (insert, alter, delete, get).
The problem with relational databases comes with the JOIN statement with theses consequences :
- developers create a new table every time there is a possibility of dissociation in the data, which leads usually to plenty of tables. The “relation” between entries in different tables is made through the use of ID fields… The first drawback is the maintenance and complexity. Developers have developed tools in order to visualize and maintain the relations, which leads to unreadable documents. Here is an example for a small company :

-
in order to get a result, requests have to merge different tables, which is made through the use of
JOINstatements. Performance decrease fast when list of data to join is not a singleton, but also, usually it leads to multiple JOIN statements in each query that are hard to read. -
developers have developed some frameworks such as Active Records for Ruby, which requires to learn lots of convention and is language dependent.
-
the search approach, with filters applied on fields of linked tables, is not that easy to implement on relational databases, and is not as effective as a search engine.
The document approach
To replace relational databases, the solution I used so far is to create “documents” stored by NoSQL databases and indexed by search engines. To avoid the growing number of tables:
-
instead of having secondary tables, I store strings that can describe the variable information directly in the main document. For example, facet ID
1378becomesSHOES. The search engine can retrieve all existing values thanks to aggregation queries. -
data that would normally be in secondary table is directly written into the main document. This leads to duplicate information, information that is the same in different documents. Such duplicates can be very useful when edition of one document should not impact another document. This is the case, for example, of the supplier name in invoice documents : if the supplier name changes, we don’t want former invoices to change. On the contrary around, if edition has to impact all duplicates, a simple search query can find all the documents to edit.
This solution is not a fully satisfying solution.
TinkerPop standardization effort
The best solution to such a problem is certainly the use of a technology which will contain all the work in front of the databases, instead of writing your own code or use code frameworks.
There is a new initiative from Apache called TinkerPop3 :
TinkerPop3 solves many of the requirements and defines a standard such as the SQL standard.
TinkerPop3 also provides an interactive console, a REST API, a server and can work with different underlying databases (HBASE, Cassandra, DynamoDB, Neo4j … ).
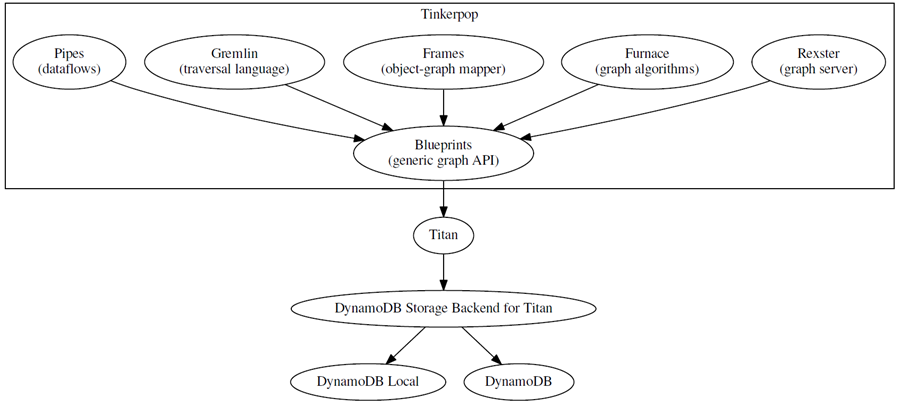
The analog of JDBC for TinkerPop standard is Blueprints.
On top of Blueprints,
as well as pipes, object wrappers or graph algorithms.
AWS implemented Blueprints for DynamoDB thanks to Titan technology.
Here is a great schema from AWS (thanks to @AWS) :
Install, launch Gremlin and execute traversals on graphs
Install and launch TinkerPop3 Gremlin :
cd technologies
wget https://www.apache.org/dist/incubator/tinkerpop/3.0.0-incubating/apache-gremlin-console-3.0.0-incubating-bin.zip
unzip apache-gremlin-console-3.0.0-incubating-bin.zip
rm apache-gremlin-console-3.0.0-incubating-bin.zip
cd apache-gremlin-console-3.0.0-incubating
./bin/gremlin.shExecute a traversal on the modern graph example :
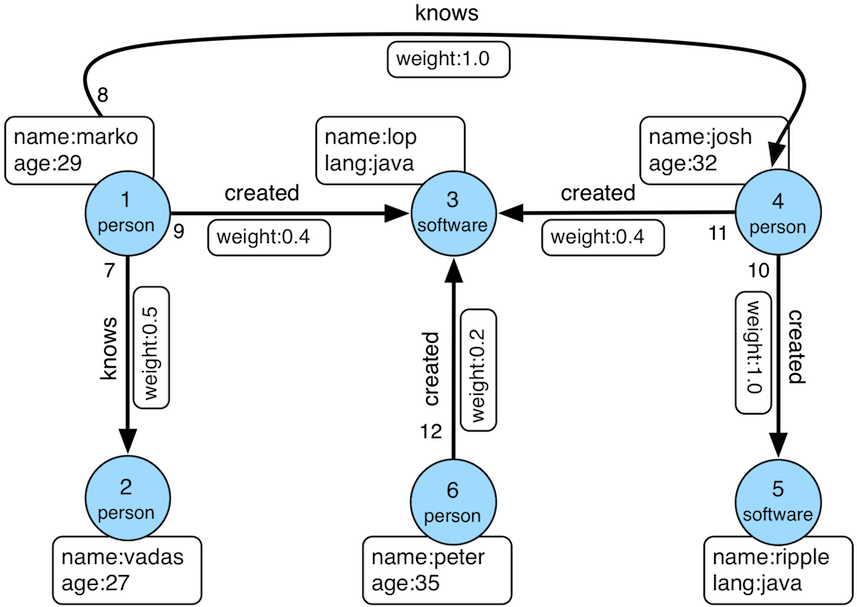
graph = TinkerFactory.createModern()
g = graph.traversal(standard())
g.V().repeat(groupCount('m').by(label)).times(10).cap('m')Test a bulk-optimized traversal on the Grateful Dead Graph example :

graph = TinkerGraph.open()
graph.io(graphml()).readGraph('data/grateful-dead.xml')
g = graph.traversal(standard())
clockWithResult(1){g.V().both().barrier().both().barrier().both().barrier().count().next()}Well done !