Object detection deep learning frameworks for Optical Character Recognition and Document Pretrained Features
Working as AI architect at Ivalua company, I’m happy to announce the release in the open source of my code for optical character recognition using Object Detection deep learning techniques.
The main purpose of this work is to compute pretrained features that can serve as early layers in more complex deep learning nets for document analysis, segmentation, classification or reading.
Object detection task has been improving a lot with the arise of new deep learning models such as R-CNN, Fast-RCNN, Faster-RCNN, Mask-RCNN, Yolo, SSD, RetinaNet… These models have been developped on the case of natural images, on datasets such as COCO, Pascal VOC, … They have been applied to the task of digit recognition in natural images, such as the Street View House Numbers (SVHN) Dataset.
These object detection models have sometimes been applied to documents at the global document scale to extract document zones, such as tables or document layouts. But documents are very different from natural images, mainly black and white, with very strong image gradients and very different gradient patterns. These object detection models are all based on pretrained features coming from classification networks on natural images, such as AlexNet, VGG, ResNets, …, included in the cases quoted on document images, but might not be suited to document, in particular at character scale, since they are not the standard architecture to recognize characters, but also probably at the global document scale.
The classification network basis for document images could certainly be better found in networks developped for the MNIST digit dataset, such as the LeNet. The idea is to explore the application of object detection networks to character recognition with network architectural backbones inspired by these digit classification networks, better suited to document image data.
The code has first been developped on toy examples, built with MNIST data:
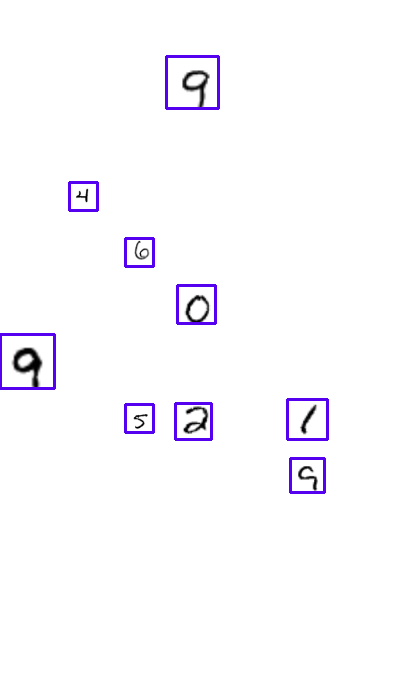

Training on the full document images is challenging, since
-
characters could be hardly read when the document size is less than 1000 pixel high,
-
classically, training deep learning networks for image tasks is usually performed on small sized images, less than 300 pixels high and wide (224, 256, …) to fit on GPU.
So, in order to keep a good resolution to read the characters and a document image small enough to fit on the GPU, as classically in object detection, we first used crops, as well as multiple layers as in SSD to recognize characters at different font sizes:


Once the results were good enough, document image resolution and batch size have been decreased to fit the image and the network in the GPU, and the following result has been achieved, dropping the characters of size too big or too small:
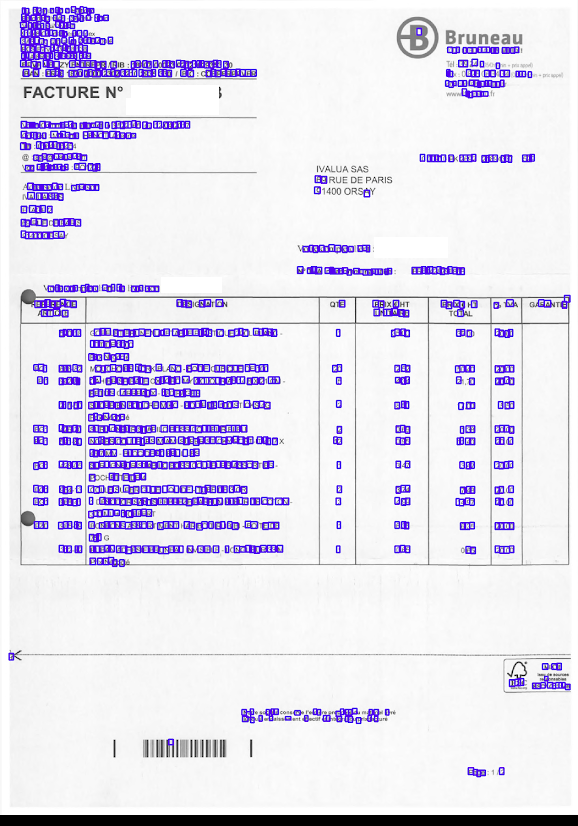
The full experiment settings and results are described in the PDF paper.
By releasing our work, we hope to help open source community use and work with us on these nets, to invent more accurate or more efficient networks for full document processing, that could serve as early layers for further document tasks.
Well done!